Hey,
some days ago I read in the Hama-dev mailing list about the Nutch project that want a PageRank implementation:
Hi all,
Anyone interested in PageRank and collaborating w/ Nutch project? :-)
So I thought, that I can do this. I already implemented PageRank with MapReduce. Why don’t we go for a BSP version?:D
This is basically what this blog post is about.
Let’s make a few assumptions:
- We have an adjacency list (web-graphs are sparse) of webpages and their unweighted edges
- A working partitioning like here. (You must not implement it, but should know how it works)
- We have read the Pregel Paper (or at least the summary)
- Familiarity with PageRank
Web Graph Layout
This is the adjacency list. On the leftmost side is the vertexID of the webpage, followed by the outlinks that are seperated by tabs.
1 2 3
2
3 1 2 5
4 5 6
5 4 6
6 4
7 2 4
This will be pretty printed a graph like this:
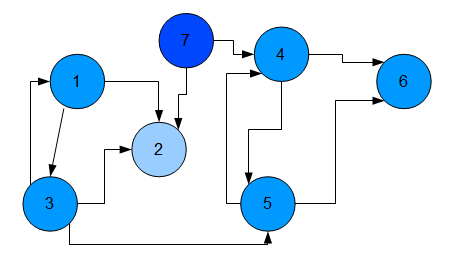
I have colored them by the incoming links, the vertex with the most in-links is the brightest, the vertex with few or no in-links is more darker.
We will see that vertex 2 should get a high PageRank, 4, 5 and 6 should get a more or less equal rank and so on.
Short summary of the algorithm
I am now referring to the Google Pregel paper. At first we need a modelling class that will represent a vertex and holds its own tentative PageRank. In my case we are storing the tentative PageRank along with the id of a vertex in a HashMap.
In the first superstep we set the tentative PageRank to 1 / n. Where n is the number of vertices in the whole graph.
In each of the steps we are going to send for every vertex its PageRank, devided by the number of its outgoing edges, to all adjacent vertices in the graph.
So from the second step we are receiving messages with a tentative PageRank of a vertex that is adjacent. Now we are summing up these messages for each vertex “i” and using this formula:
P(i) = 0.15/NumVertices() + 0.85 * sum
This is the new tentative PageRank for a vertex “i”.
I’m not sure whether NumVertices() returns the number of all vertices or just the number of adjacent vertices. I’ll assume that this is the count of all vertices in the graph, this would then be a constant. Now adding the damping factor multiplying this by the sum of the received tentatives of the adjacent vertices.
We are looping these steps until convergence to a given error will be archived. This error is just a sum of absoluting the difference between the old tentative PageRank and the new one of each vertex.
Or we can break if we are reaching a iteration that is high enough.
We are storing the old PageRank as a copy of the current PageRank (simple HashMap).
The error will thus be a local variable that we are going to sync with a master task- he will average them and broadcasts it back to all the slaves.
Code
Let’s look at the fields we need:
private static int MAX\_ITERATIONS = 30;
// alpha is 0.15/NumVertices()
private static double ALPHA;
private static int numOfVertices;
private static double DAMPING\_FACTOR = 0.85;
// this is the error we want to archieve
private static double EPSILON = 0.001;
HashMap<Integer, List<Integer>> adjacencyList = new HashMap<Integer, List<Integer>>();
// normally this is stored by a vertex, but I don't want to create a new
// model for it
HashMap<Integer, Double> tentativePagerank = new HashMap<Integer, Double>();
// backup of the last pagerank to determine the error
HashMap<Integer, Double> lastTentativePagerank = new HashMap<Integer, Double>();
Keep in mind that every task just has a subgraph of the graph. So these structures will hold just a chunk of PageRank.
Let’s get into the init phase of the BSP:
@Override
public void bsp(BSPPeerProtocol peer) throws IOException, KeeperException,
InterruptedException {
fs = FileSystem.get(getConf());
String master = conf.get(MASTER\_TASK);
// setup the datasets
adjacencyList = mapAdjacencyList(getConf(), peer);
// init the pageranks to 1/n where n is the number of all vertices
for (int vertexId : adjacencyList.keySet())
tentativePagerank
.put(vertexId, Double.valueOf(1.0 / numOfVertices));
...
Like we said, we are reading the data chunk from HDFS and going to set the tentative pagerank to 1/n.
Main Loop
// while the error not converges against epsilon do the pagerank stuff
double error = 1.0;
int iteration = 0;
// if MAX\_ITERATIONS are set to 0, ignore the iterations and just go
// with the error
while ((MAX\_ITERATIONS > 0 && iteration < MAX\_ITERATIONS)
|| error >= EPSILON) {
peer.sync();
if (iteration >= 1) {
// copy the old pagerank to the backup
copyTentativePageRankToBackup();
// sum up all incoming messages for a vertex
HashMap<Integer, Double> sumMap = new HashMap<Integer, Double>();
IntegerDoubleMessage msg = null;
while ((msg = (IntegerDoubleMessage) peer.getCurrentMessage()) != null) {
if (!sumMap.containsKey(msg.getTag())) {
sumMap.put(msg.getTag(), msg.getData());
} else {
sumMap.put(msg.getTag(),
msg.getData() + sumMap.get(msg.getTag()));
}
}
// pregel formula:
// ALPHA = 0.15 / NumVertices()
// P(i) = ALPHA + 0.85 \* sum
for (Entry<Integer, Double> entry : sumMap.entrySet()) {
tentativePagerank.put(entry.getKey(),
ALPHA + (entry.getValue() \* DAMPING\_FACTOR));
}
// determine the error and send this to the master
double err = determineError();
error = broadcastError(peer, master, err);
}
// in every step send the tentative pagerank of a vertex to its
// adjacent vertices
for (int vertexId : adjacencyList.keySet())
sendMessageToNeighbors(peer, vertexId);
iteration++;
}
I guess this is self explaining. The function broadcastError() will send the determined error to a master task, he will average all incoming errors and broadcasts this back to the slaves (similar to aggregators in the Pregel paper).
Let’s take a quick look at the determineError() function:
private double determineError() {
double error = 0.0;
for (Entry<Integer, Double> entry : tentativePagerank.entrySet()) {
error += Math.abs(lastTentativePagerank.get(entry.getKey())
- entry.getValue());
}
return error;
}
Like I described in the summary we are just summing up the errors that is a difference between the old and the new rank.
Output
Finally we are able to run this and receive a fraction between 0 and 1 that will represent the PageRank of each site.
I was running this with a convergence error of 0.000001 and a damping factor of 0.85. This took about 17 iterations.
\------------------- RESULTS --------------------
2 | 0.33983048615390526
4 | 0.21342628110369394
6 | 0.20495452025114747
5 | 0.1268811487940641
3 | 0.0425036157080356
1 | 0.0425036157080356
7 | 0.02990033228111791
This will result in about 1.0 in the sum of all ranks, which is correct.
Note that the output if you are running this job is not guaranteed to be sorted, I did this to give you a better view.
We’ll see that we were quite good in our guessing of the PageRank in the beginning.
I think this is all, if you are interested in testing / running this- feel free to do so.
This class and test data is located in my Summer of Code repository under: http://code.google.com/p/hama-shortest-paths/
The classes name is de.jungblut.hama.bsp.PageRank.
Just execute the main method, it will run a local multithreaded BSP on your machine.
Star this project and vote for my GSoC task. :)
Thank you.