Hey all,
I had a bit time to get my k-means clustering running with BSP and Apache Hama. I wanted to share this with you.
Actually this is a sequel to a series that I have announced long ago: Series: K-Means Clustering (MapReduce | BSP).
You may remember that I have already made a post about K-Means and MapReduce, now I want you to show that k-means clustering with BSP is much faster than the MapReduce one.
Don’t expect a benchmark in this post, but I will give you a real comparision a bit later once Apache Hama 0.4.0 rolls out.
So this post is mainly about the algorithm itself and what my ideas were to make it running and scalable.
I’m going to make a next post which is containing more code and explain more clearly how it works. But code is still changing, so this will take a bit more time.
Quick note right at the beginning: As I mentioned it, I am currently developing with a Apache Hama 0.4.0 SNAPSHOT, since it hasn’t been released yet.
Let’s step into it!
Model Classes
We need some kind of Vector and something that is going to represent our Center.
These are very basic, actually it is just a wrapper object with an array of doubles and some convenience methods. A Center is just the same like a Vector, but it also adds some more methods to detect if it has converged or averaging two centers.
You can have a look on Github at them if you’re interested.
Idea behind k-means with Apache Hama’s BSP
Before really showing you the algorithm in the source code, I’d like to tell you what my plan and intention was.
In a typical clustering scenario you will have much much more points than centers/means. So n >> k (”>>” for much larger than), where n is our number of vectors and k is our number of centers.
Since Apache Hama 0.4.0 will provide us with a new I/O system it makes it really easy to iterate over a chunk of the input on disk over and over again, we can use this fact and put all our centers into RAM.
The trick in this case is that unlike in graph algorithms, we do not split the centers over the tasks, but every task holds all k-centers in memory.
So each task gets a part of the big input file and every task has all centers.
Now we can easily do our assignment step, we just iterate over all input vectors and measure the distance against every center.
While iterating we find the nearest center for each of the n vectors. To save memory we are going to average our new center “on-the-fly”. Follow the Average in data streams article on Wikipedia, if you’re not familiar with it.
At the end of the assignment step, we have in each task the “on-the-fly” computed average new centers.
Now we are going to broadcast each of this computed averages to the other tasks.
Then we are going to sync so all messages can be delivered.
Afterwards we are iterating in each task through the messages and averaging all incoming centers if they belong to the same “old” mean.
I know this is difficult to explain, but please consult this picture, it is about the exchange of the locally computed mean for two tasks.
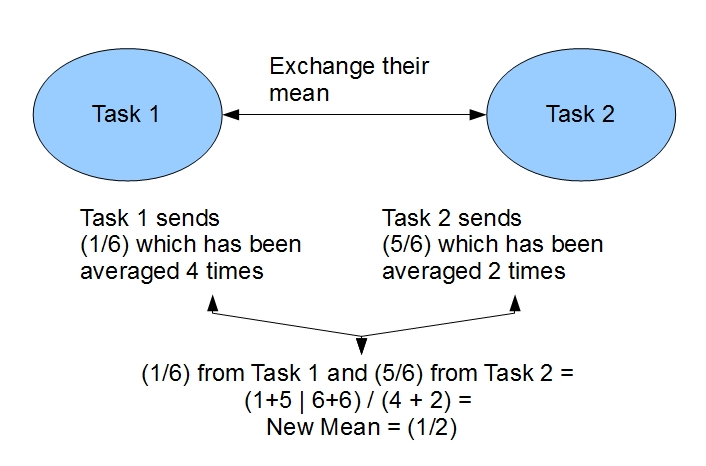
Message exchange with mean calculation
As you can see on this picture, we have two tasks which have calculated “their version” of a new mean. Since this isn’t the “global mean” we have to calculate a new mean that will be consistent across all the tasks and is still the correct mathematical mean.
We apply the “Average on data streams” strategy. Each task is going to get the local computed averages from each other task and is reconstructing the global mean.
Since this calculation is the same on every task, the means are still globally consistent across the tasks just with the cost of one global synchronization. Fine!
Actually this is the whole intuition behind it. As the algorithm moves forward, this whole computation is running all over again until the centers converged = don’t change anymore.
This is much faster than MapReduce, because you don’t have to submit a new job for a new computation step.
In BSP the superstep is less costly than running a MapReduce job, therefore it is faster for this kind of tasks.
When you plot the result, you come up with something that looks like this:
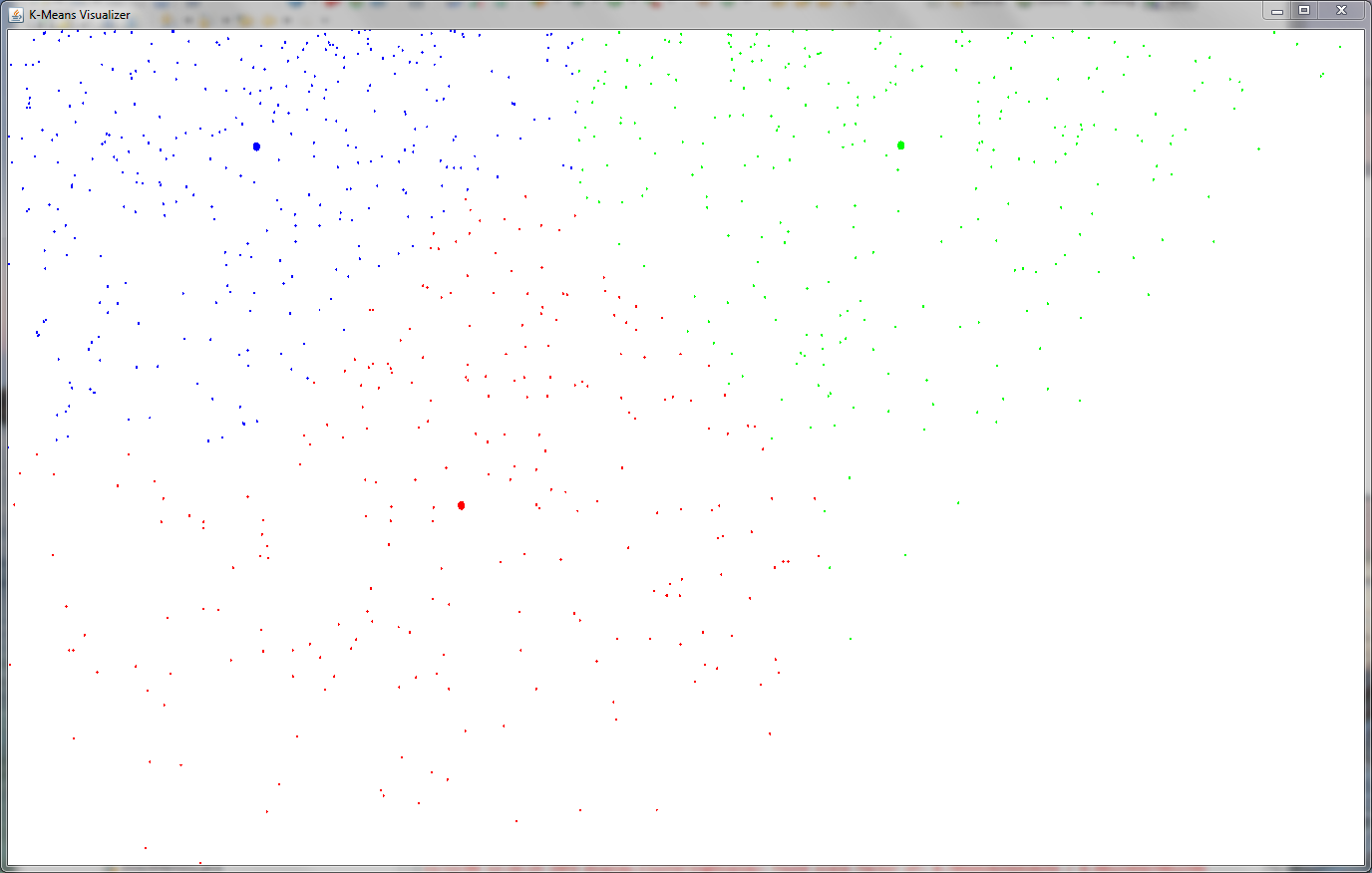
K-Means BSP Clustering with K=3
In one of the upcoming posts, I’m going to explain you the code in detail.
If you are interested in the code and can’t wait, you can have a look at it in my Github here:
K-Means BSP Code
The code will randomly create some vectos and assigns k initial centers to the first k-created records. You can run it via a main-method in your IDE or to your local-mode Hama cluster.
See you!