Hey all,
it has been quite a long time since my last blog post. Thanks to my work, to keep me busy all day and don’t let me research on cool new things. However, over the few holidays and weekends over the last weeks I came across a very interesting algorithm called DBSCAN.
It is abbreviated for ”density-based spatial clustering of applications with noise”, it is a unsupervised clustering algorithm just like k-means, besides that it is much smarter in many aspects.
Another objective I’d like to solve is the parallelization of this algorithm. I’ve seen just some ancient papers and what buffels me is that I’ve seen no implementation in Mahout (for MapReduce) or other distributed frameworks.
As you may know, I’m working for Apache Hama. It is a framework for distributed computing with the BSP (bulk synchronous parallel) model. I always searching for new algorithms that could fit into the model of BSP computing, e.G. graph algorithms of all sorts, strongly iterative algorithms, real-time algorithms.
And I think that DBSCAN also fits into the BSP model, I tell you why a bit later in this post.
First off, just a little introduction of the DBSCAN algorithm itself…
The algorithm
The algorithm is very easy to understand. Actually you have a bunch of points (or vectors in higher dimensionalities) as input, then you have to parameters and some fancy output.
The two parameters are called “epsilon” and “minpoints”, epsilon is the minimum distance between two vectors to connect two points strongly and minpoints is the number of points that are at least needed to build a cluster out of strongly connected vectors.
Now you are going through the graph, point by point, marking visited vectors and adding points to a cluster while they are not violating the rules defined by epsilon and minpoints.
You can read on wikipedia about how the sequential version works in detail, however I am going to propose a much more easier to understand version of the algorithm.
Distributed algorithm steps
Instead of defining a big distributed algorithm that translates the sequential version into some distributed programming model, I have assembled three main steps to get the same result as the sequential version.
However each of these steps are strongly parallelizable in every major programming model (at least I know how it works in MapReduce, BSP and MPI).
Here are the three steps:
- compute a distance matrix between the vectors with a given distance measurement
- trivial step to parallelize, can also be merged with the next point
- extract adjacent points via the epsilon threshold and the minpoints restriction
- This step creates an adjacency list/matrix representing a graph
- Noise is filtered at this step of the algorithm
- run a connected component algorithm on the resulting graph of the previous step
- Already done that in MapReduce and BSP, the last BSP version will be updated shortly after Apache Hama 0.5.0 comes out.
These three simple steps will give you the same result as a DBSCAN. Normally you can merge step 1 with step two, you can simply extract the adjacents points while computing the distances.
In the end, you will receive n-connected components, every of them will represent a cluster.
The delta to the points of your original input would be the noise cluster.
Note that the initial step is O(n²) which is obviously pretty bad and not scalable. So think about techniques like Similarity Hashing to speed this step up.
Pretty easy right? I think it is even more easier than the pseudocode on wikipedia.
Of course I put up a sample version (albeit sequential) on my github repo. There is also the original DBSCAN algorithm for comparison.
There is a nice plot I received when running it:
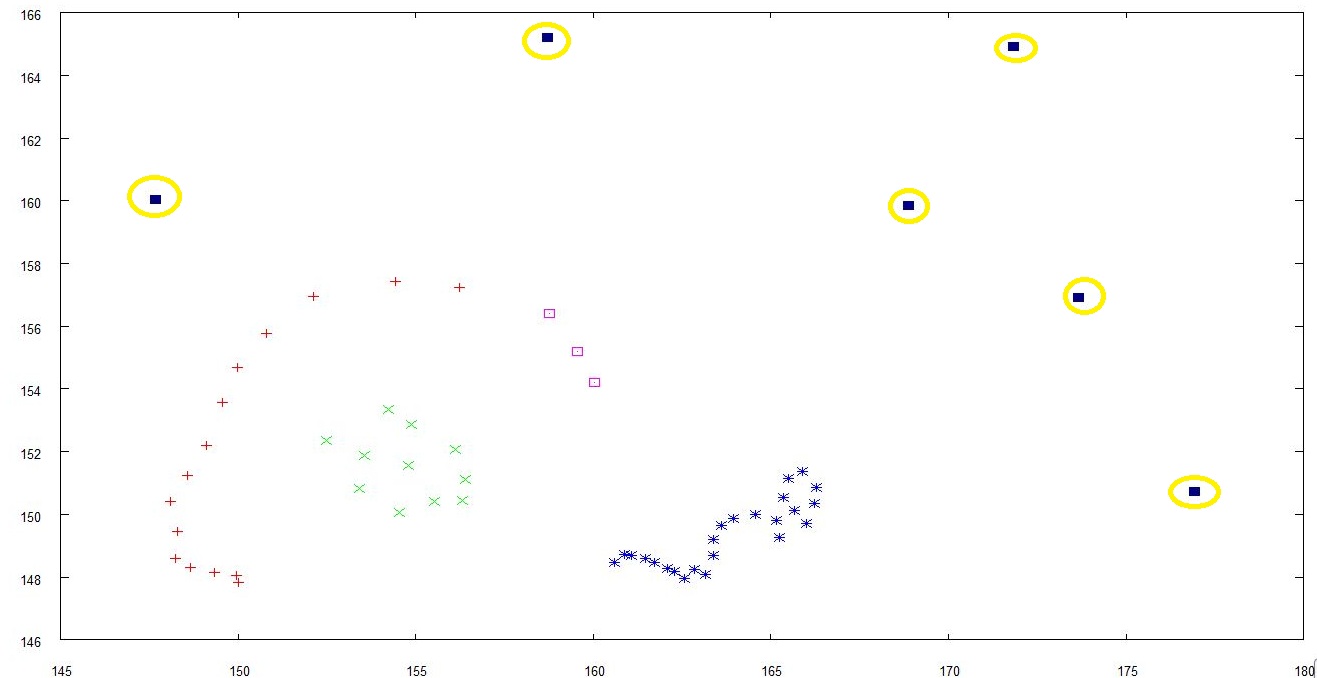
To make the noise more easy to spot, I have made horrible yellow circles arround them with Paint, please forgive me ;)
So far I haven’t found the time to implement this whole system with Apache Hama. However, if you want to practically use this here are some advices:
- For the distance matrix to compute, better use a heuristic to find close vectors
- Mahout has a MinHashing implementation of such a clustering
- Once you obtained “mini” clusters, you can compute more expensive distance measurements and extract your graph (step two in the above list)