Hi there,
today is about realtime processing with Apache Hama.
One day, Edward told me about a guy, who told him, that he uses Hama for realtime processing.
At first this is quite a strange/new thing, because inherently BSP is used (just like MapReduce) for batch processing. It has several advantages over MapReduce, especially in graph and mathematical use cases.
I think this new “feature” is the greatest advantage over MapReduce.
Let me clarify a bit how it works.
At first you will have some tasks which are going to be our so called event collectors. In my example this will be a single master task.
Anyways, the trick is now that the event collectors are waiting for new events to come, or even poll for new events that happened, they do it in a while loop. Something which is possible in MapReduce though.
Now you can built a producer/consumer pattern on top of this. Which just says, your event collectors are messaging computation tasks to do some computation on the data we have just sent. This will allow you to do more complex stream analysis in near-realtime.
We will see this in an example a bit later.
Why is this better than a MapReduce job?
If you run a MapReduce job, you can straight poll for data available inside a while loop, too. But without a messaging system between the tasks you are forced to write your data into HDFS to make it available for a broader amount of tasks to parallelize your workload.
Since Hadoop has lots of job scheduling and setup overhead, this is not realtime anymore. That is now degenerating to batch processing.
For those of you who are familiar with Giraph, it is similar to that MapReduce Job, where tasks messaging with other MapReduce tasks. Sadly they just focused on graph computing and are strongly dependend on input from filesytem.
Example: Realtime Twitter Message Processing
Yes, we can analyse Twitter data streams in BSP in realtime!
What do we need?
- Twitter Library, in this case Twitter4J
- Latest Hama, in this case this is a 0.4.0 snapshot. You can use 3.0 as well, with minor code changes.
Let’s dive directly into it and look how to setup the job.
HamaConfiguration conf = new HamaConfiguration();
// set the user we want to analyse
conf.set("twitter.user.name", "tjungblut");
// I'm always testing in localmode so I use 2 tasks.
conf.set("bsp.local.tasks.maximum", "2");
BSPJob bsp = new BSPJob(conf);
bsp.setJobName("Twitter stream processing");
bsp.setBspClass(DataStreamProcessing.class);
bsp.waitForCompletion(true); I think this is pretty standard, the trick is here to set the desired username of the guy who you want to analyse.
In my case this is my twitter nick “tjungblut”.
I omit the setup method and the fields now, if you have questions on what I’ve done there, feel free to comment on this post.
The real (time) processing
Let’s step directly to the processing and the mimic of the producer/consumer pattern.
The idea is simple: A master task is polling for new “Tweets” and is sending this directly to our computation tasks (fieldname is otherPeers, which contains all tasks but the master task).
This happens while our computation tasks are waiting for new “food” to arrive.
Once our computation tasks get a message, they can directly start with their computation.
Let’s see how the master tasks is doing the job:
@Override
public void bsp(BSPPeer bspPeer) throws IOException, KeeperException,
InterruptedException {
if (isMaster) {
while (true) {
// this should get us the least 20 tweets of this user
List<Status> statuses = twitter.getUserTimeline(userName);
for (Status s : statuses) {
// deduplicate
if (alreadyProcessedStatusses.add(s)) {
System.out.println("Got new status from: "
+ s.getUser().getName() + " with message " + s.getText());
// we distribute messages to the other peers for
// processing via user id partitioning
// so a task gets all messages for a user
bspPeer.send(
otherPeers\[(int) (s.getUser().getId() % otherPeers.length)\],
new LongMessage(s.getUser().getId(), s.getText()));
}
}
// sync before we get new statusses again.
bspPeer.sync();
... // computation task stuff Note: I’ve ommitted a lot of details (try/catchs) and pre-mature optimizations which can be found in the code.
As you can see the event collector (aka master task) is polling the twitter API to get the newest tweets of a given user.
Now the master is sending the new messages to our computation task.
Note that there is a simple trick to distribute the work equally to the tasks. In our case we have just a single user we are listening on, and two tasks. So this won’t do anything but sending this directly to another task.
You can change this behaviour by either listening to the public timeline or changing the distribution of the message by using the message id instead of the user id. I hope you get the gist ;)
In short: We are listening to a specific user and therefore every message goes from the collector directly to the computation task. In our case we have only 2 tasks, so increasing the tasks will just cause one task to be idle the whole time.
Let’s have a look at the slave task (aka computation task).
This is very simple:
// we are not the master task... so lets do this:
} else {
while (true) {
// wait for some work...
bspPeer.sync();
LongMessage message = null;
while ((message = (LongMessage) bspPeer.getCurrentMessage()) != null) {
System.out.println("Got work in form of text: " + message.getData()
+ " for the userid: " + message.getTag().longValue());
}
}
}
As you can see, this is a pretty simple consumer.
You could now add some logic to it. For example to track the communication between a person and others: How often, how much and what content.
In my case, this looks like this:
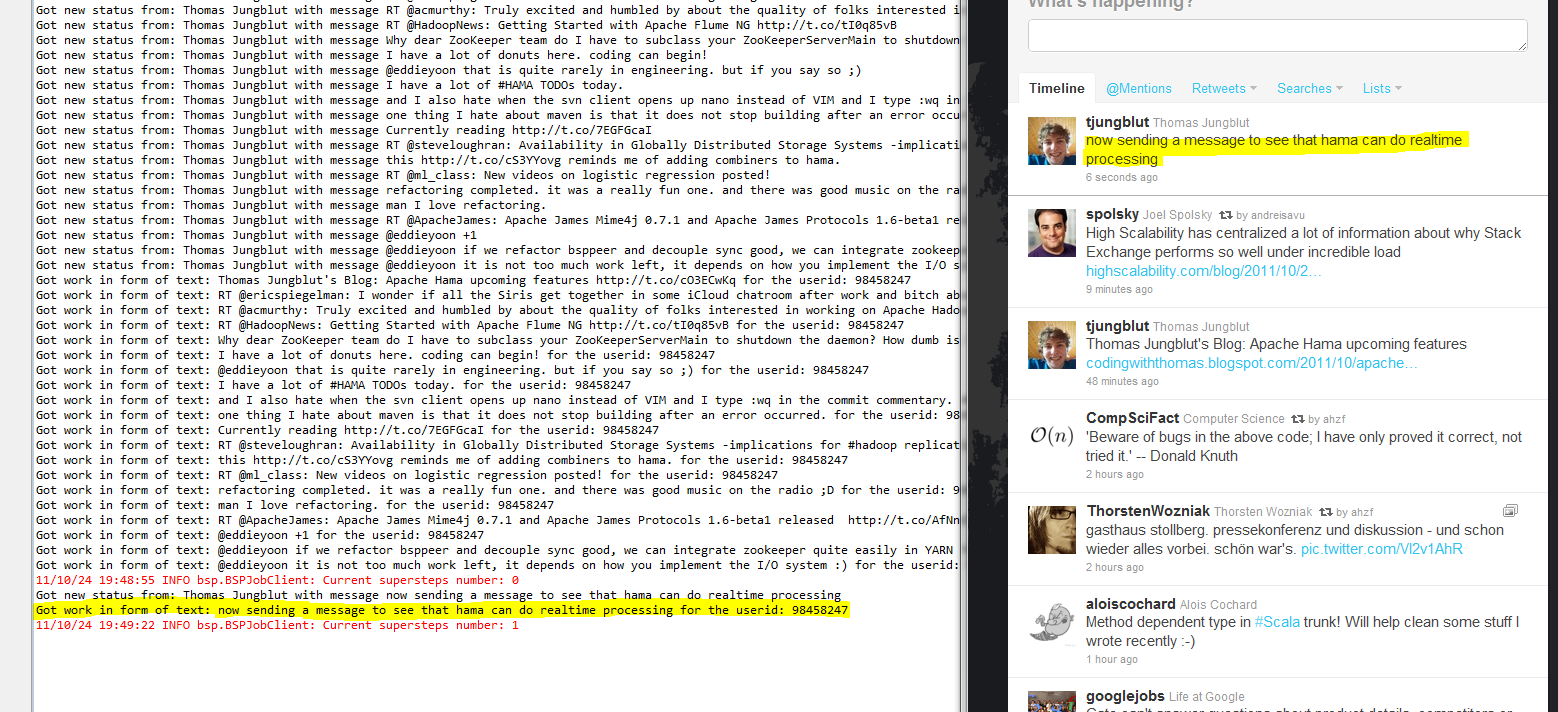
Note that it directly came up after it has been send.
Now, this is a real cool thing!
Imagine:
If you would have unlimited access to the public timeline (sadly this is capped by 150 requests/h) and you have enough computational power in your cluster, you can do your own trending topics!
Of course you can do everything else you want to.
I hope this has been quite “illuminating” for you and shows you how to enable realtime processing if you have Hama.
Of course you can checkout my sourcecode my github. The class we just talked about is available here:
Have fun and good luck!