Hey guys,
my work phase is over and I’m back to university next week so I’m having a bit more time to write here.
The first free time yesterday focussed on generating random data for Apache Hama / Apache Whirr and for my pagerank algorithm. HAMA-420 is the related issue on Jira.
After a lot of stress with the broken DMOZ file, I came along that partitioning takes far to long for some (1-3) million vertices. I already knew this issue, because it always took nearly 10 minutes to partition the sequencefile (1,26GB) of my SSSP(Single Source Shortest Paths) algorithm.
Where were the problems?
Actually, there were two major problems I saw.
- Structure of the in- and output File
- Zlib Compression
So first off the structure, for SSSP it looked like:
K / V
Vertex[Text] / AdjacentVertex : Weight [Text] Every line contained one(!) vertex and it’s adjacent. Someone of you might notice that this is quite verbose. We used this structure for both, the input and the partitioned files.
The second thing is the standard compression that comes with SequenceFiles, it is the zLib codec which you have to explicitly turn off. Otherwise compression takes nearly 80% of the writing time without any real effort in file sizes.
How to deal with it?
These two problems were quite easy to solve. The first thing is to change structure and put adjacent vertices along with their origin vertex into one line of input textfile.
To be quite general for inputs I sticked with textfiles (this is very common and readable in every editor) and directly write into a sequencefile which is key/value composal of a vertex and an array of vertices.
Processing
The new architecture works on the input textfile and reads each line and passes it into an abstract method.
So everyone can implement their own input-textfile-parser and put it into the vertex the BSP needs. Which then gets directly partitioned via hash and gets written into the sequencefile of the groom.
Later on we have to extend this with various stuff of compression, inputformat, recordreader and other partitioning ways.
The groom will then just read the sequencefile objects and will put them into ram. So no more text deserialization has to be done: CHEERS!
Comparision new vs old
The result is overwhelming! See it in my Calc Sheet:
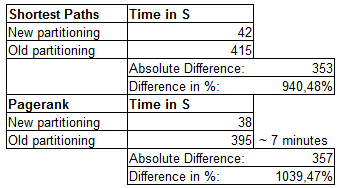
This is just a great improvement. It get’s comitted as HAMA-423.
Thanks and Bye!